IPv6.watch - Sometimes the results are off
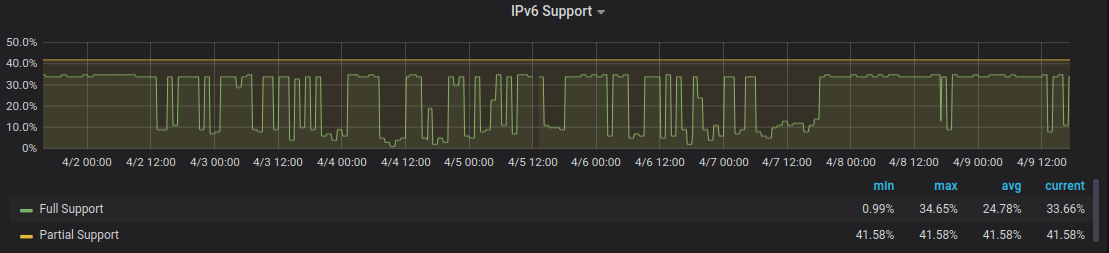
Initially I thought it would be some temporary issue with Hetzner (where the VM is hosted) and their networking. So I briefly looked through the enormous amounts of (unhepful) logs the service generated, did some manual poking and after not seeing any apparent errors on my side declared it transient and closed the case.
This afternoon I decided to give it another look.
I fired up my local Grafana development environment that spawns a local (ephemeral) clone of the production Grafana instance and started tinkering with the data.
My first attempt was to figure out if some specific site (aka a website) is impacting the overall results. Most of the available visualisations didn’t really look like a good fit for my needs. Looking through the Grafana plugins page and I eventually found the statusmap plugin and gave it a shot:
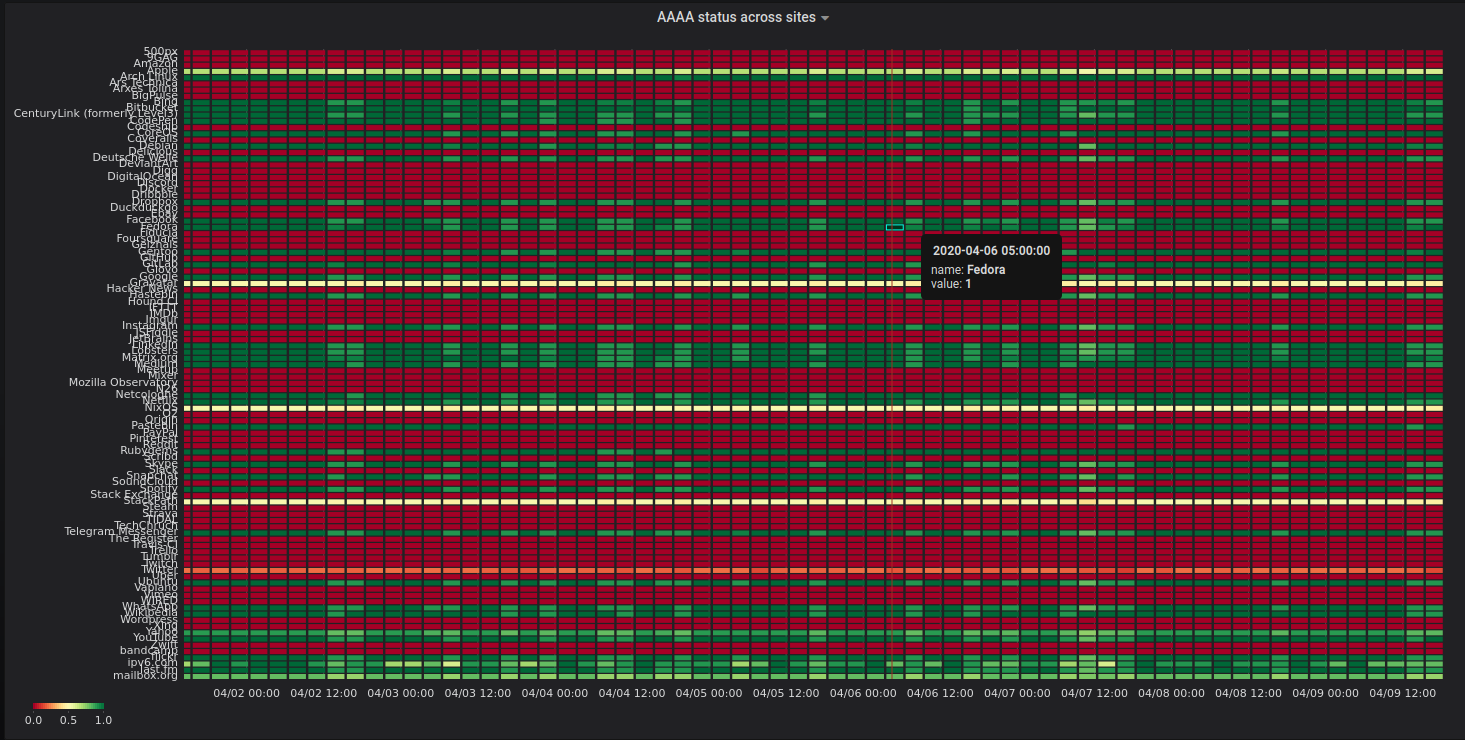
While that graph looks fancy there isn’t much you can take away from it with a quick glance. It has waaaaay too much information. Next try was to aggregate the data over the providers that I am querying:
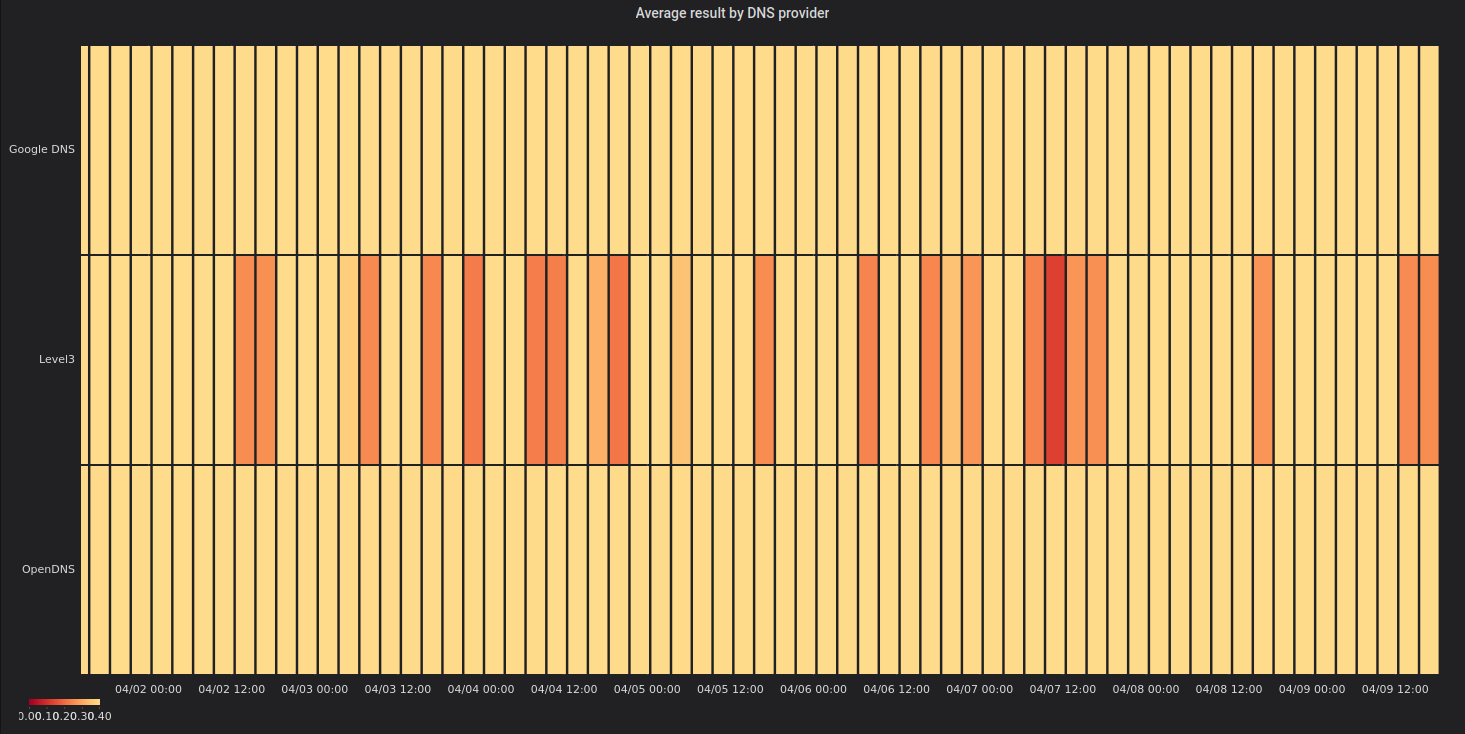
This time the results look a lot more helpful. So something seems to be up with Level3’s public DNS service. Let’s take a closer look at how individual resolvers are doing:
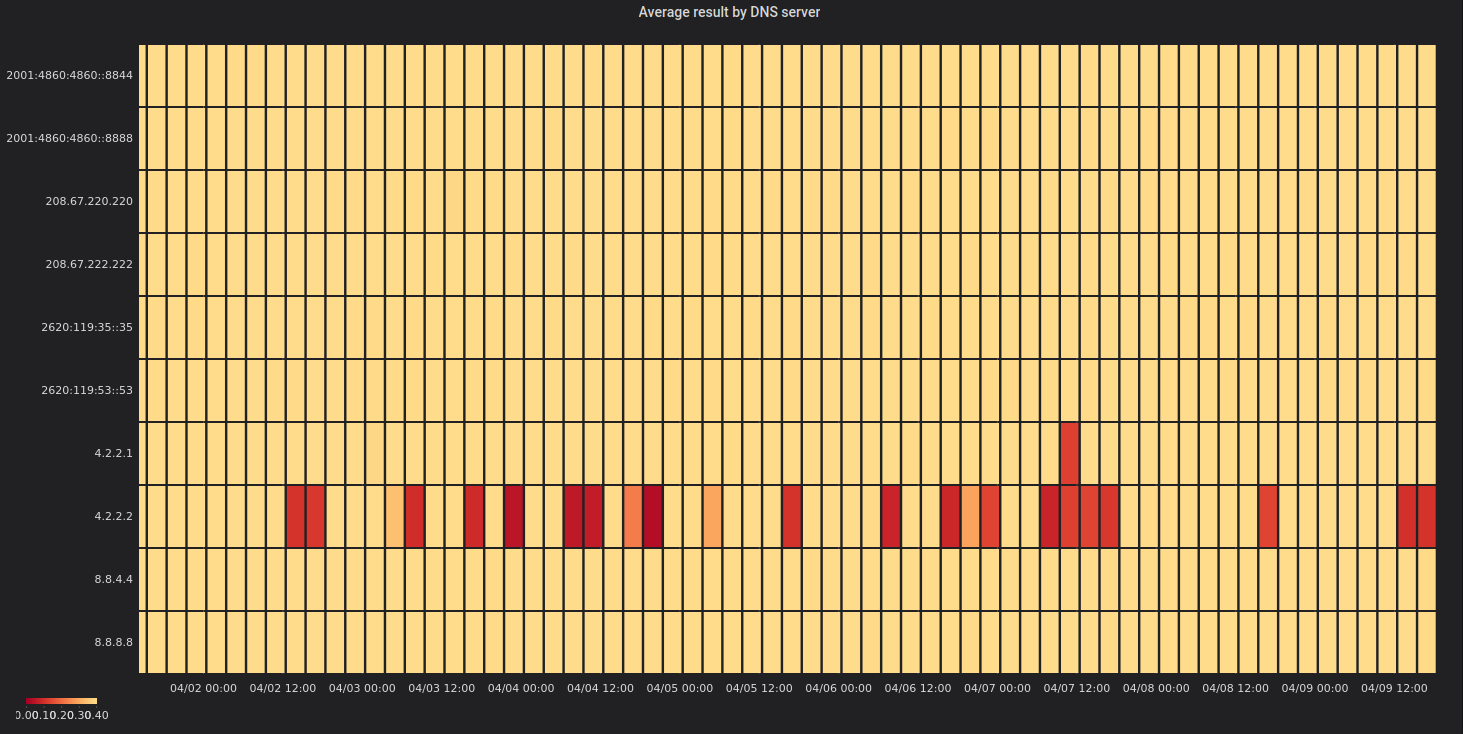
Aha! So there is this one resolver 4.2.2.2 that is very flaky with it’s
sister 4.2.2.1 that also isn’t doing great at all times.
I took a brief look at today’s RIPE BGPlay history for
4.0.0.0/9
but that looked pretty stable. It probably isn’t some global routing issue.
Since I didn’t want to invest more time I setup two RIPE Atlas measurements to see if those errors are occurring for others (from 100 random places on the planet) as well:
- One of them checks the DNS resolution of
youtube.comby4.2.2.2: https://atlas.ripe.net/measurements/24653529/ - The other one checks of
4.2.2.2can be reached via ICMP echo: https://atlas.ripe.net/measurements/24653530/
Next time this issue bugs me I can hopefully just pull up those measurements and have a look at the results.